
Overview
Our project, the Infinity Machine, is an application useful for efficient management of textual information of any kind, say research material. It allows users to store information by the their title, type, details and multiple tags and allows for easy search, retrieval, edit and delete functions. Intended to be used through the Command Line Interface, and targeted at tech-savvy, university students looking for an efficient, simple yet powerful way of maintaining their resources.
Major enhancement:
1. Modified the ability to search through sources:
Modification:
Format: search [n/TITLE] [y/TYPE] [d/DETAILS] [t/TAG] [t/TAG]…
The work I have done on AB4’s search feature can be divided into 3 major modifications as follows:
-
Multiple prefix tags of different (and same) kinds: The search function now has an added functionality of being able to take in multiple arguments of the same and different type of source fields [except author], and search for sources based on its conjunction.
-
Substring matching with incomplete words: It is enabled with substring matching as against exact field matching. Each argument is checked for its presence inside the source fields and a source is found only if all the user entered arguments are present inside the source’s respective field values.
-
Auto-correction feature for typing mistakes: It is also able to find string matches with minor typing errors in the spelling, implemented using Levenshtein distance or the edit distance. The implementation current accounts for less than 5 character swaps needed to transform between the strings entered by the user and the entire field value of sources.
What it does:
It allows the user to search through all the entries in the database through various fields at a time, same and different, and display source entries that satisfy all of the entered tags in conjunction, with substring matching and typo accommodation. It allows compound searches to be made, allowing user to narrow down their search, hence helping in efficient retrieval of the sources, and making working on the database more efficient. It also reduces the onus on the user to remember and recall the source entries maintained by allowing them to enter as many consecutive characters for a field value they can enumerate.
Justification:
This feature improves the product significantly because a user can now search an entry with a particular title AND a particular type and so on. Furthermore, it removes the reliance on the user to memorize exact field values, by enabling substring matching and multiple tags entered so the user can enter as much as he remembers and see the results.
It helps user greatly narrow down their search should they be looking for a specific source entry with particular values, instead of cluttering the screen with all those sources with share the same title as the one the user searches using the command. It also allows user to search sources based on other fields and not just title, such as type, tags and details, and even their logical combination, along with allowing the user to not memorize his source fields.
Highlights:
-
This enhancement does not affect existing commands and commands to be added in future.
-
However, it changed the format of the original
searchcommand, which now not only takes parameters of different types, but also needs them to be prefixed by their CLI delimiters. -
If any seemingly unwanted results are displayed after a search command is executed, it should not be seen as a bug as this is the intended behaviour because of the two features that render the search result space more broadened than before [substring matching and typo accommodation].
-
Rest assured, the intended results will never be missed out.
Credits:
Most of the feature was developed independently, with some design and implementation considerations discussed with fellow team members.
Minor enhancement:
1. Modified the ability to list sources:
Modification:
Format: list [N] [M]
Inside [] means optional.
The new modification to the command changes its format optionally, allowing user to be able to pass either one, two or no parameters and list only those many sources from the entire source list.
The various formats now accepted are:
-
listwith no arguments: Works as the originallistcommand and shows all the sources and their details, unfiltered. -
list Nwith one positive argument: Shows the top N sources with all their details only. -
list -Nwith one negative arguments: Shows the last N sources or the Top N sources from the bottom with their details. -
list N Mwith two positive arguments: With M>=N, shows sources between the indices N and M (included) with all their details only.
All these resulting sources are appropriately numbered as 1, 2 .. and so on regardless of their index in the original source list.
What it does:
It allows the user to now pass optional arguments to list command and then displays only those indexed source entries in the original source database as per the cases above.
The original working of the list command showing all entries is still maintained, with now 3 added functionalities.
Justification:
This feature improves the product significantly because a user can now list only as many item he wants and need not clutter the screen by displaying all.
It helps him to narrow down his search by being able to specify what indices of the original sources (say by time of addition) what he like to view. This ensures more effective retrieval and
operations on the sources, such as following it by index dependent operations such as edit and delete for instance.
Highlights:
-
This enhancement does not affect existing commands and commands to be added in future.
Credits:
Most of the feature was developed independently, with some design and implementation considerations discussed with fellow team members.
Code contributed:
[Reposense contribution]
Search Command:
[main search command logic]
[search command test]
[search command parser test]
List Command:
[main search command logic]
[list command test]
[list command parser test]
Other contributions:
Project management:
-
Helped in maintaining issue tracker and milestone progress, along with managing project releases and reviewing and merging pull requests.
-
Helped in refactoring Storage AP in migrating the codebase from AB4 to The Infinity Machine for our team, helped in refactoring the entire Storage package to be compatible with the functionalities required by our application, mostly changing identifier names and method signatures to model our application’s scope. Updated Storage class diagram in the Developer Guide.
-
Assign PE-dry-run bug issues to relevant team members for fixing by the final milestone.
Enhancements to existing features:
-
Fixed failing test cases of AB4 to accommodate the modified command formats, for both
searchandlist. -
Adding relevant test cases for both
searchandlistto test the various use cases of the commands and specifcally some problematic edge cases. -
Enhanced javadocs for implemented methods to make their functionality and logic more relevant to our application’s scope, changing parameter and return type along with modifying format and functionality explanation.
Documentation:
-
Added to and updated the User Guide
-
Added to and updated the Developer Guide
-
Added to and updated the ContactUs.adoc
-
Added to and updated the AboutUs.adoc
-
Added to and updated the README.adoc
Community:
-
Reviewed and approved PRs of other team mates [40 PRs approved]
-
Opening and assigning relevant issues during product ideation phase and whenever feedback was received.
-
Helped in tracking issues including assigning severity, status, type, and closing it.
Tools:
-
Set-up Coveralls
Contributions to the User Guide
Given below are sections I contributed to the User Guide. They showcase my ability to write documentation targeting end-users. |
Listing all sources : list
Displays a list of sources currently in the database, filtering by number and position depending on the [optional] parameters passed.
Takes 1 or 2 optional argument which are used to list only the top/bottom N sources or the sources between N and M (included) indices respectively.
With one parameter passed, a positive N lists top N sources from the top, a negative N lists top N sources from the bottom [bottom N sources].
With two parameters, the range must have both N and M as positive indices and N must not be smaller than M.
None of the values can ever be 0. The listing feature is always relative to the original list of the entire database.
Format: list [N] [M]
where argument N and M in [ ] are optional [either enter none, N, or (N and M)]
The four main formats and their usages are described below:
list: (no arguments)
When no arguments are passed to list, it works same way as in the original AB4 logic, listing all the sources in the entire database with all their title, type, author, detail and tag values.
The sources are unfiltered and listed in entirety, with indexes 1, 2.. so on.
Example: list
Lists all the sources indexed from 1 onwards with all their details.
list N: (one positive argument)
When one positive integer is passed to list, it lists the first N sources from the top, again listing all their title, type, author, detail and tag values.
Top N sources are listed with respect to the original source database list with indexes 1, 2 … till N.
Example: list 5
Lists top 5 sources from the entire database indexed from 1, 2 .. 5 with all their details.
list -N: (one negative argument)
When one negative integer is passed to list, it lists the last N resources from the top or first N sources from the bottom, again listing all their title, type, author, detail and tag values.
Bottom N sources are listed with respect to the original source database list with indexes 1, 2 … till N.
Example: list -5
Lists the last 5 sources from the entire database indexed from 1, 2 .. 5 with all their details.
list N, M: (two positive arguments)
When two positive integers are passed to list, it lists the sources between N and M (included) from the top, again listing all their title, type, author, detail and tag values.
N to M sources are listed with respect to the original source database list with indexes 1, 2 … till (M-N+1).
Example: list 6, 9
Lists the 4 sources from index 6 to 9 from the entire database list, indexed from 1, 2 .. till 4 with all their details.
|
The maximum possible index that will be processed by the system is limited to the largest positive value for a 32-bit signed binary integer. Any number larger than 2,147,483,647 will not be parsed as an integer and will be rejected. |
Searching a source: search
Searches for entries amongst the list of sources.
Able to search by title, type, detail and tags as specified by the CLI prefixes [author field not included].
Able to perform substring matching. Able to implement autocorrect by searching for 'similar' strings,
where similarity is defined by a pre-set Levenshtein distance as against the entire field value (and not substring)
Finds all entries with a (case insensitive) field value that contains the value as specified by the user.
Searches with multiple arguments are taken as conjunction searches, i.e all those sources
that satisfy all the keyword values are shown (logical and operation).
Enables substring matching for a more powerful retrieval of sources. Also able
to take in multiple arguments of each prefix and search
in conjunction such as all those fields are matched with the corresponding fields of the resulting sources.
Similar fields are also shown, allowing for room should the user have made a typing mistake, or the user meant something
else, or the user just wants to see other related sources with similar field values.
If any seemingly unwanted results are displayed after a search command is executed, it should not be seen as a bug and this is
the intended behaviour because of the reasons and rationale explained above or in the Developer Guide.
Rest assured, the intended results will never be missed out.
Format: search [i/TITLE] [y/TYPE] [d/DETAILS] [t/TAG]…
Examples:
-
search i/Algorithms
Returns the source(s) with the titlealgorithms -
search i/wiki y/web d/intelligence t/ML
Returns any source(s) having tagsMLand having the wordintelligencesomewhere in their content (detail) and having a type ofwebsiteorweb series. -
search i/data i/algo
Returns the source(s) with both substrings 'data' and 'algo' included in them. -
search y/wesbiteReturns the source(s) of type 'website' [and other similar strings, if any]
Contributions to the Developer Guide
Given below are sections I contributed to the Developer Guide. They showcase my ability to write technical documentation and the technical depth of my contributions to the project. |
List feature
Current Implementation
The list command is facilitated by Infinity Machine.
It extends Infinity Machine with a list functionality, enumerating all or a specific number of
entries in the source database and their all their details, in the order of their addition, or custom order
as may be supported by the application.
The four main formats and their usages are described below:
1. list: (no arguments)
When no arguments are passed to list, it works same way as in the original AB4 logic, listing all the sources in the entire database with all their title, type, author, detail and tag values.
The sources are unfiltered and listed in entirety, with indexes 1, 2.. so on.
Example: list
Lists all the sources indexed from 1 onwards with all their details.
2. list N: (one positive argument)
When one positive integer is passed to list, it lists the first N sources from the top, again listing all their title, type, author, detail and tag values.
Top N sources are listed with respect to the original source database list with indexes 1, 2 … till N.
The number N must be a positive, non-zero number for the command logic to work. A negative N alludes to the 3rd case below.
Example: list 5
Lists top 5 sources from the entire database indexed from 1, 2 .. 5 with all their details.
3. list -N: (one negative argument)
When one negative integer is passed to list, it lists the last N resources from the top or first N sources from the bottom, again listing all their title, type, author, detail and tag values.
Bottom N sources are listed with respect to the original source database list with indexes 1, 2 … till N.
The number after the negative sign but be a non-zero positive number for the command logic to work.
Example: list -5
Lists the last 5 sources from the entire database indexed from 1, 2 .. 5 with all their details.
4. list N M: (two positive arguments)
When two positive integers are passed to list, it lists the sources between N and M (included) from the top, again listing all their title, type, author, detail and tag values.
N to M sources are listed with respect to the original source database list with indexes 1, 2 … till (M-N+1).
For valid functioning of the command, the two numbers passed must be positive and the first number must not be greater than the second number.
I.e. both numbers should be non-zero and the second number can only be same or greater than the first number to produce a valid listing of the sources.
Example: list 6 9
Lists the 4 sources from index 6 to 9 from the entire database list, indexed from 1, 2 .. till 4 with all their details.
Some salient features which affect the command’s working are discussed below:
-
An argument passed which more than the current number of sources in the list is reduced to the index of the last source [i.e. the maximum number of sources]. For example, executing
list 100when the database has only 50 entries will automatically cap its display to 50 instead of throwing an error. Similarly, for other command formats too, the listing is capped by the total number of sources and the success message is too altered appropriately. -
Any number of arbitrary spaces between the list command word and its argument is accepted. The
command parserwill look for the valid command word and whenlist commandis called, then the numbers will be plucked out in the right order and the appropriate command format will be executed. For example, 'list 2 3', ' <n spaces> list <x spaces> 2 <y spaces> 3 <z spaces> ' all commands work in the same, intended fashion for all values of n and z and all non-zero values of x and y. -
More than two arguments are ignored and only the first two arguments are evaluated as per the 4th case above. Thus,
list 2 3 4andlist 2 3 4 …all are executed aslist 2 3only. -
This list feature controls how many sources [based on indices passed] are displayed, with respect to the original source list only, and not the one currently being displayed to the user. Thus, if
list 2 4is carried out afterlist 7 10then the list index 2, 3 and 4 of the original list will be outputted and not of this currently displaying list. Similarly, if a user executeslist 3post an operation, say search, then the first three sources of the entire databae are shown and not the first three sources of the filtered list of the resulting search operation. -
Having said (4), the new displayed list of sources after the executing of any list operation will update the internally maintained current list displayed, thus any operation [such as
edit,delete] which are based on the indexes of the current displaying list will still function as per normal after a list command is executed. For example, after displayinglist 3 5, if a user executesdelete 1, it is akin to deleting the 3rd source in the entire list database.
The sequence diagram of the working of the list command is as below:
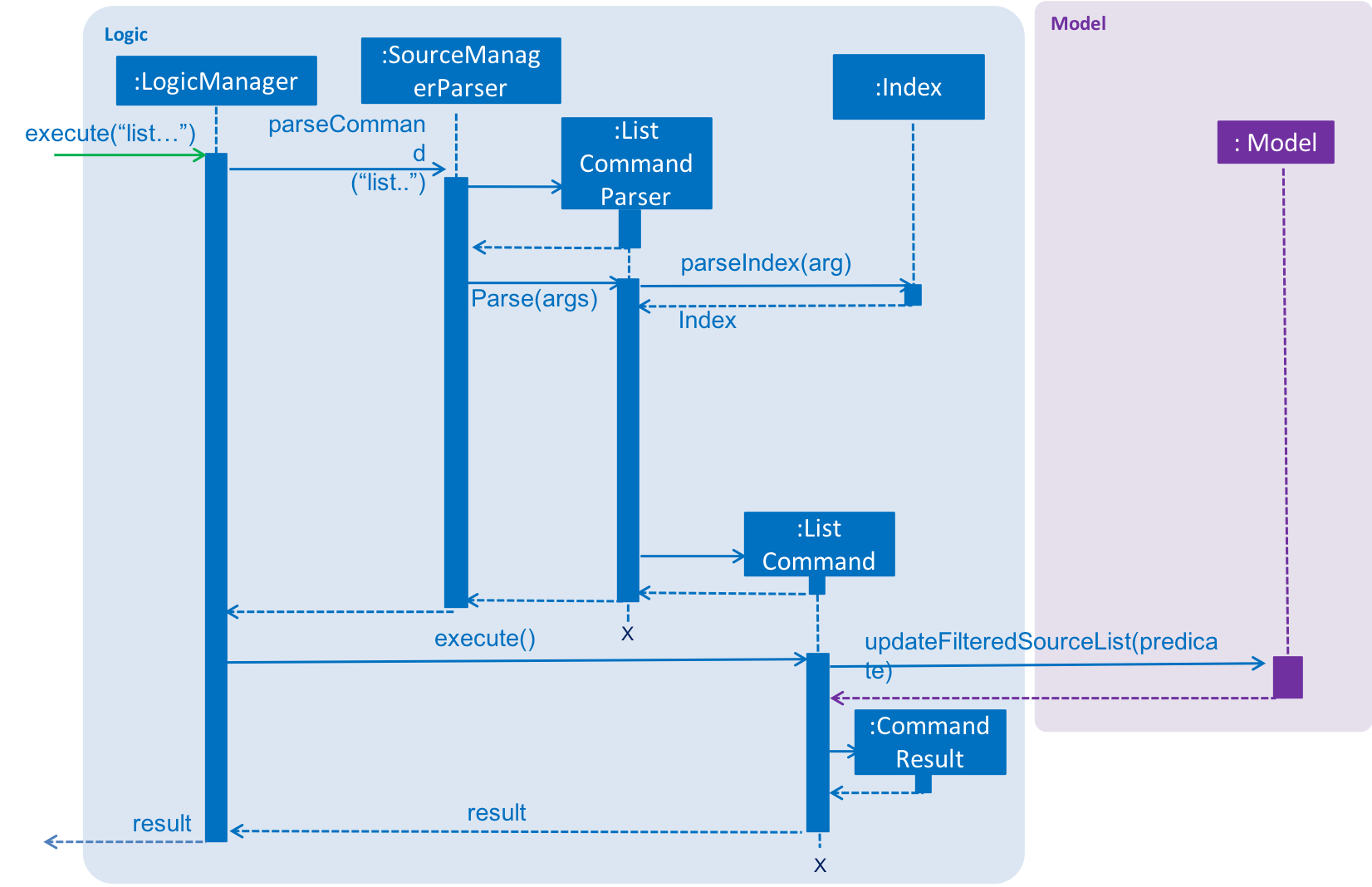
Motivation for such an enhancement is that one may feel that such act of populating all the sources on the GUI may be cluttering the view unnecessarily. Now, what could be the parameters a user may want to limit the list by? Limiting merely by their field values is akin to search, which would make the logic redundant. In contrast, the user may want to control the number of sources he wants to view, or be able to limit by some sense of the time at which it was added.
This could be helpful in:
-
Iteratively examining all the sources by restricting how many are shown at one time. The user may begin with listing
list 10, thenlist 11 20and so on to analyze all the source entries 10 at a time. -
Making more effective use of the GUI display to the user by not unnecessarily enumerating all sources, but rendering it more powerful by allowing the user to control what and how many sources he wants to see the details of.
-
Enabling a pseudo-filtering by time-of-addition of the sources, something the application logic does not support currently [e.g. TimeAdded field]. This is possible because the list command alway alludes to the original databse list of all the sources, which are by defaul maintained in the order of their addition [with most recent at the end].
Thus, the new modification to the command changes its format optionally, allowing user to be able to pass either one, two or no parameters and list only those sources which have their indices falling in the range entered [as covered by the cases above]. This may be intuitively useful when say you want to perform certain operations in this new list of sources that are displayed by their time of addition, since the sources are by default arranged in descending order of their time of addition.
Example, a user wants to delete all of the sources that were added yesterday. And if 10 entries were added yesterday,
the user could just execute list 10 to access those entries and then perform a delete <INDEX> accordingly.
The original working of the list command showing all entries is still intact, when the command is called without any parameter, thus
this modification just appends extra functionality which renders the command more useful and powerful than it was before in AB4.
Additionally, it uses:
-
PREDICATE_SHOW_ALL_SOURCES— when the user does not pass an argument to the list command, all sources must be displayed. This predicate resultstruefor every source tested. Also, this filtering mode is internally called before any list operation so the command is able to utilize the entire database list in its filtering logic and not just the one currently displayed. -
makePredicateForTopN— when the user passes a positive argument, only first N sources must be listed. This method returns a new object of typePredicate<Source>that keeps track of thecountof sources, evaluatingtruefor the first N sources andfalsefor all the rest. -
makePredicateForLastN— when the user passes a negative argument, the last N sources must be listed. This method returns a new object of the typePredicate<Source>that keeps track of thecountof the sources, evaluatingtruefor the las N sources anfalsefor all others. -
makePredicateForXToY— when the user passes two positive arguments, the sources between the two indices (included) must be listed. This method returns a new object of the typePredicate<Source>that keeps track of thecountof the sources, evaluatingtruefor all sources between indices N and M included, andfalsefor all others. -
targetIndex— the number N up to which the most recent sources are to be displayed to the user, in both the positive N and negative N case (case 2 and 3). It is maintained internally. Set to the current size of the database if the value input is more that this current size. -
fromIndex— in the case of two arguments, this is the first index, must be non-zero positive number not greater than thetoIndexbelow. -
toIndex— in the case of two arguments, this is the second index, must be non-zero positive number not less than thefromIndexabove. -
posFlag— internally maintained, passed astruefor positive single argument N andfalsefor negative single argument N.
This feature improves the product significantly because a user can now list only as many item he wants and need not clutter the screen by displaying all.
It helps him to narrow down his search, say should he want to view the N first or last added sources. This ensures more effective retrieval and
operations on the sources, such as following it by index dependent operations such as edit and delete for instance.
Some points to note:
- This enhancement does not affect existing commands and commands to be added in future.
- It required an in-depth analysis of design alternatives. Especially when it came to adding the ability
for the command to be able to work both with 1 parameter and no parameters.
Some design considerations were
Using variable arguments: in parser method of ListCommandParser class, but this would require changing the
Interface Parser<T>. This technique did not work for making ListCommand objects for the same reason.
Using method overloading: This did not work for parser method because of the interface restrictions, however
this was used in the constructor of LogicCommand class, creating two objects depending on whether a targetIndex was passed
or not, and whether two indexes where passed or none.
** Using args.length(): Ultimately used in parse method for a simple check whether an
argument is passed and how many are passed.
- The implementation too was challenging, as the current format of list command had to be changed and be prepared to accept and parse optional arguments, with the choice of
either one or two parameters, ie. implementing overloading functionality
for the list command logic based on whether the number of arguments passed by the user if any.
Given below is an example usage scenario and how the list mechanism behaves.
Step 1. The user launches the application for the first time. The Infinity Machine will be initialized with the initial source database state, by default listing all the sources
in an indexed fashion, with all details and in order of their addition.
Step 2. The user executes an add command to add another source entry to the database.
Step 3. The user executes list command (with no arguments). All the entries in the database are listed again, showing all the details and
in the order of their addition.
Step 4. The user now executes delete to delete an entry.
Step 5. The user executes list command again. All the updated entries in the database, leaving out the last deleted one, are listed again, showing all the details and
in the order of their addition.
Step 6. The user now executes list 2 command. The first 2 entries akin to the previous output are displayed.
Step 7. The user now executes list 3 5 command. The source entries 3, 4 and 5 are shown, indexed as 1, 2 and 3, with all their details.
Step 8. The user now executes list 3 command. The first 3 entries of the entire source database are listed with all their details, and not the first three of the currently
showcased list.
Step 9. The user now executes list -2 and the last two sources from the entire database list (and not the currently displayed list) are shown.
Step 10. The user now executes delete 1 and the first entry of the current list or the second last entry of the entire database is deleted.
Design Considerations
Aspect: How list, list N, and list N M executes
-
List (current choice): Filters using predicate that returns
truefor every source.-
Pros: Easy to implement.
-
Cons: May have performance issues in terms of time usage.
-
-
List N (current choice): Filters using predicate that returns
truefor first/last N sources.-
Pros: Easy to implement. Intuitive to understand
-
Cons: Can be made faster and cleaner using List operations or streams.
-
-
List N (current choice): Filters using predicate that returns
truefor sources between N and M included.-
Pros: Easy to implement. Intuitive to understand
-
Cons: Can be made faster and cleaner using List operations or streams.
-
Aspect: Data structure to support the list/list N/list N M commands
-
Alternative 1 (current choice): Forms predicates based on the input parameter, maintain targetIndex, fromIndex, toIndex and posFlag.
-
Pros: Uses simple
countparameter initialized to 0 or 1 and incremented each time a source is evaluated returningtrue/falsedepending on the format of the list command. Easy for new Computer Science student undergraduates to understand, who are likely to be the new incoming developers of our project. -
Cons: Maybe not the best implementation in terms of the number of internal flags and indices maintained.
-
Search feature
Current Implementation
Format: search [n/TITLE] [y/TYPE] [d/DETAILS] [t/TAG] [t/TAG]…
The search feature is facilitated by Infinity Machine.
It extends Infinity Machine with an find feature, allowing user to search through source entries by the title, type, detail and/or tags, with substring matching.
This search function now has an added functionality of being able to take in multiple arguments of the type of source fields [i.e. title, type, detail and tags], and search for sources based on that. It searches in conjunction using multiple fields including title, type, detail and tag(s) input by the user, listing only those sources that satisfy all the input constraints of the matching fields, with all there corresponding field values.
Another addition to its functionality is that this search feature is enabled with substring matching as against exact field matching.
This renders this feature more powerful as the user may not always be able to remember exactly the title or tag of the source.
It’s major usage is in the fact that the user will store the bulk of their data in the details field, and it is unintuitive to have them
list the entire contents of the source in order to match and search it. Thus now, the user is only required to search using
as many consecutive words they are able to recall to narrow the listings.
How it works is, it allows the user to search through all the entries in the database through various fields at a time, and display source entries that satisfy all of the entered tags in conjunction, by checking if the source value contains these parameters. It allows compound searches to be made, allowing user to narrow down their search, hence helping in efficient retrieval of the sources, and making working on the database more efficient.
Lastly, the search is able to find string matches with minor typing errors in the spelling. This feature renders the search more powerful by accommodating any minor typing error user may make when keying in their search argument. This includes minor flips of two characters or a missing character or few extra characters etc. The implementation current accounts for less than 5 character swaps needed to transform between the strings.
| Auto-correction feature only works when entire field value is entered and not for substring matching. |
i.e. misspelling a single word in the title will not be caught unless the entire title is entered, then the user entry will be matched against the entire title to see if there are less than 5 corrections needed to transform between the two strings.
However, it may seem that such an additional renders the search feature a bit too general, thus making the search output space broadened by including more sources that would have otherwise been ignored. But, one may see this as an advantage as:
-
Obviously, this is targeted at accounting for the slightest chance that the user may have made a typo.
-
If not, this feature at the very least shows user 'similar' or 'other related' entries that may be useful in their research project as they search for a particular entry. This can help in giving user more ideas about related sources in the same field.
This distance is know as the Levenshtein distance or the edit distance, after the Russian scientist Vladimir Levenshtein who devised the algorithm in 1965. This algorithm is used to determine how different two strings are from each other by outputing the integer number of transformations (insertions, deletions and substitutions) needed to transform one string to the other.
The algorithm implementation for this section of the code was inspired from Baeldung.
| If any seemingly unwanted results are displayed after a search command is executed, it should not be seen as a bug and this is the intended behaviour because of the reasons and rationale explained above. Rest assured, the intended results will never be missed out. |
Additionally, it uses:
-
SourceContainsKeywordsPredicate.java— Here, the logic of running through all the respective fields of all the sources and matching it with the user inputs (trimmed by space, case insensitive and take as substring) is implemented. It is split by the CLI prefixes and implements conjunction logic, by only returningtruefor those sources that satisfy all the constraints, i.e. have all the fields matching as entered by the user, where matching is checked by if the string contains the keywords entered by the user (case insensitive). -
checkAllEmpty— method inside SourceContainsKeywordsPredicate which checks if all the entries of all the tags is empty, and returns true thus showing all sources. -
levenshtienDist— returns the number of swaps needed to transform one string to the other -
checkLevenshtienSimilarity— returns true if the number of swaps needed, as returned bylevenshtienDistabove is less than theLEVENSHTIEN_DISTANCE_CONSTANTbelow -
LEVENSHTIEN_DISTANCE_CONSTANT— a positive integer which determines the number of swaps a string can have for it to pass the similarity test as per thecheckLevenshtienSimilaritymethod. Currently set to 5, thus if less than 5 swaps are needed to convert between the user entered string and the entire string value fo the source field.
Given below is a sequence diagram representation of the search command of the Infinity Machine:
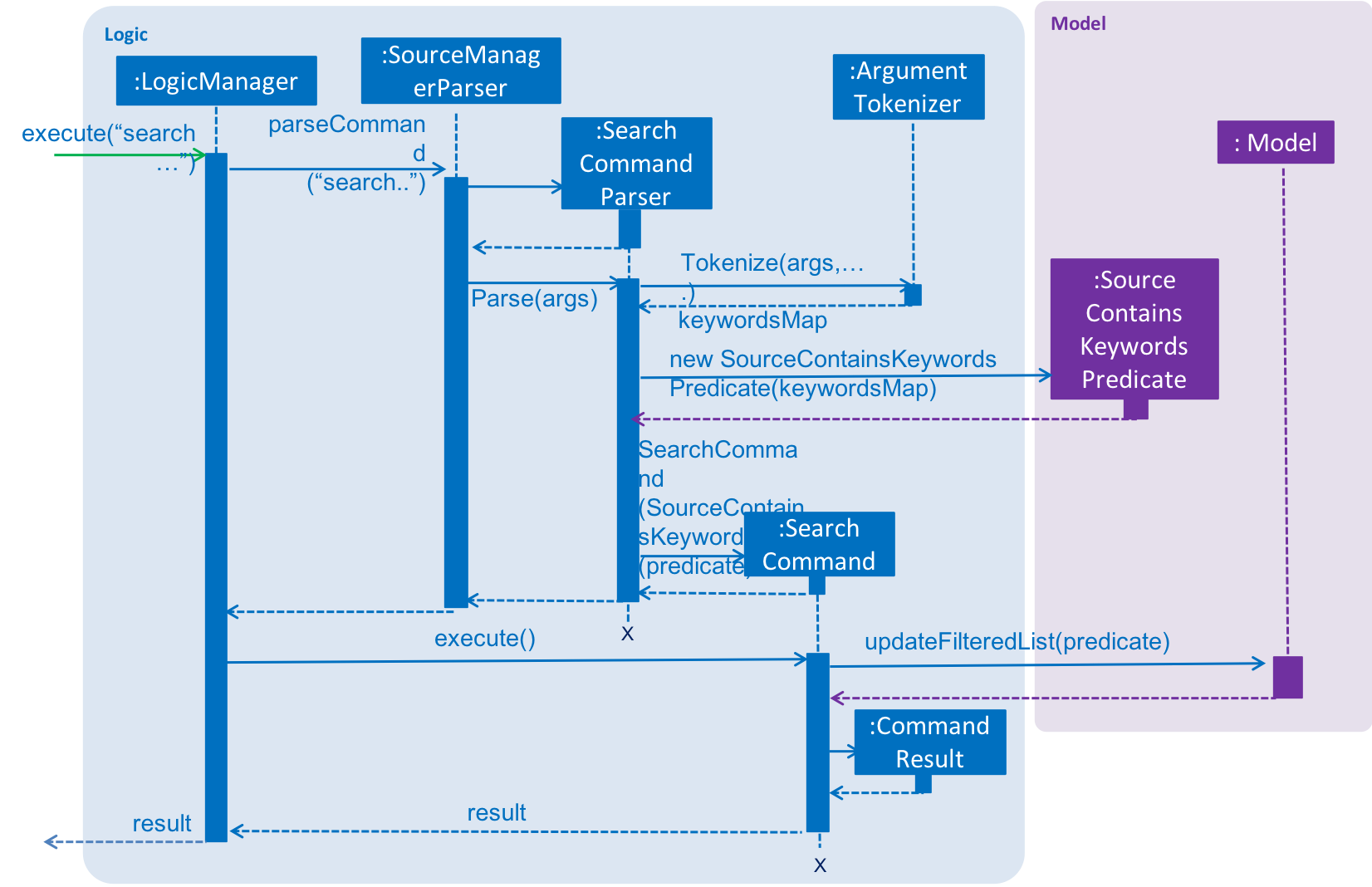
This feature improves the product significantly because a user can now search an entry with a particular title AND a particular type and so on.
Not only that, the user can now just input whatever they are able to recall and the search returns all super strings instead of
carrying out an exact matching.
It helps user greatly narrow down their search should they be looking for a specific source entry with particular values,
instead of cluttering the screen with all those sources with share the same title as the one the user searches using the command.
It renders the search more powerful by resulting all super-strings should the user have meant something else or to prompt them about other similar
source entries containing what they are looking for.
It also allows user to search sources based on other fields and not just title, such as type, tags and details, and even their
logical combination.
Given below is an example usage scenario and how the search mechanism behaves at each step.
Step 1. The user launches the application for the first time. The Infinity Machine will be initialized with the initial source database state, by default listing all the sources
in an indexed fashion, with all details and in order of their addition.
Step 2. The user executes search i/algorithms command and only those sources that have their title as algorithms are displayed.
Step 3. The user executes search i/homework y/website and only those entries are listed that have both their title as homeowork and type as website.
Step 4. The user executes search t/CS and all those sources that have any of their tags having 'CS' in it listed, including CS2030, CS2040 and CS2103
search alone, without any arguments, will result in error. However search with empty CLI tags will output all sources. Thus, a shortcut
to display all sources is to search search i/ and a source with any title will be displayed.
|
Step 5. The user executes search i/algorihtm as a typing error, the command still displays all those sources that have their title as
algorithms or other related words exactly [not contains].
Step 6. The user executes search d/training an intelligent agent t/CS2039, the search displays all sources with
having the exact sentence 'training an intelligent agent' or any of its related similar strings in it’s body, and those with
tag 'CS2039' or any of the related modules such as 'CS2030', 'CS2040'.
Design Considerations
Aspect: How search executes
-
Alternative 1 (current choice): Runs through all entries and matches the arguments, field by field, and uing
&&operation to combine the results.-
Pros: Easy to implement as exact String matching can be done in Java using streams and
StringUtil.containsWordIgnoreCase(str1, str2). -
Cons: May have performance issues in terms of time usage.
-
Aspect: Data structure to support the undo/redo commands
-
Alternative 1 (current choice): Using streams and StringUtil functions.
-
Pros: Easy for new Computer Science student undergraduates to understand, who are likely to be the new incoming developers of our project.
-
Cons: May not be the most efficient implementation.
-
Listing sources
-
Lists sources based on the indices passed by the user
-
Prerequisites: Lists all sources when no argument passed, list top N sources when one positive integer passed, lists last N sources when one negative integer passed, lists sources from N to M (inclusive) when two positive arguments N and M are passed with N not greater than M.
-
Test case:
listExpected: lists all sources with their details -
Test case:
list 5Expected: lists top 5 sources with their details -
Test case:
list -4Expected: lists last 4 sources with their details -
Test case:
list 3 5Expected: lists sources 3, 4 and 5 with their details -
Test case:
list 5 3Expected: error because range is invalid -
Test case:
list 0Expected: error because all indices must be positive
-
Searching a source
-
Searches through the entire database of sources
-
Prerequisites: Pass values with the appropriate CLI tags to search the sources against
-
Test case:
search i/Algorithm
Expected: the source(s) with the word 'algorithm' (case insensitive and minor typo accounted for) in their entire title string will be showed, with all its details. -
Test case:
search i/AlGo i/dataa t/CS
Expected: the source(s) with their title containing both the words 'algo', 'data' and tags contain 'cs' will be displayed with all their details. -
Test case:
search i/
Expected: list all sources as title can be anything [does not throw an error]. -
Test case:
search y/web y/
Expected: the source(s) with their types containing the word 'web' will be displayed with all their details. Here, the empty tag implies the type can be anything, thus after conjunction, the 'web' constraint dominates the result.
-